ふと、キーボードの配列は文字の入力に適しているのかが気になった。
QWERTY配列は歴史的に入力効率とかを考えて作られているわけではなさそう。
文字の出現回数などを考慮して作られたキー配列としてはDvorak配列が有名。
すでに誰かが(それこそDvorak配列を生み出す過程で)まじめに考えてるだろうけど、気になってしまったので自分でも分析してみる。
今回は日本語と英語のWikipediaのデータ(の一部)を使って文字の頻度からキー配列について考える。
ついでに、隠れマルコフモデルでどの文字がどの指に対応するべきかを推論してみる。
結論から言うと、Dvorak配列はよく考えられていた。
データと前処理
wikipediaの2020/01/01のdumpデータを使う。
今回は英語と日本語について分析したいので、この二言語を次のURLから探してダウンロードする。
英語:https://dumps.wikimedia.org/enwiki/20200101/
日本語:https://dumps.wikimedia.org/jawiki/20200101/
全部のデータを使うと永遠に分析が終わらないので、いくつかの記事を適当にサンプリングして使う(後述)。
出現するすべての文字を考慮していてはキリがないので、今回はアルファベットと数字、コロンとカンマだけを対象にした。
具体的に考慮する文字種は以下のとおりである。
アルファベット:abcdefghijklmnopqrstuvwxyz
数字:0123456789
コロン、カンマ:.,
上記に含まれない文字はすべて削除した。
また、日本語はローマ字で入力されることを想定し、記事に含まれるすべてのテキストをローマ字に変換した。
日本語からローマ字への変換にはpythonのパッケージであるkakasiを使用した。
例えば、英語と日本語の前処理前、前処理後のテキストは次のようになる。
Alexander was tagus or despot of Pherae in Thessaly, and ruled from 369 to c. 356 BC.
alexanderwastagusordespotofpheraeinthessaly,andruledfrom369toc.356bc.
『メタルギアシリーズ』を長年作り続けた為か、正統続編(ナンバリングタイトル)を出すたびに「これでストーリーは完結」「次は作らない」と幾度も発言している。
metarugiashiriizuwonaganentsukuritsuzuketatameka,seitouzokuhennanbaringutaitoruwodasutabinikoredesutooriihakanketsutsugihatsukuranaitoikudomohatsugenshiteiru.
日本語の長音付(伸ばし棒)は直前の母音の連続で表記されるため,必ずしもキー入力と対応しているわけではない.
まあ,これくらいで許してください.
英語は200記事を適当にサンプリング,日本語は1万段落を適当にサンプリングした.
サンプリングの単位が違うのは特に意味がなくて,先に英語のサイズを決定した後に日本語をある程度同じサイズで揃えるためにチグハグになった.
英日のデータサイズは前処理後の文字数である程度揃えていて.具体的には以下の通り.
- 英語:2753692字
- 日本語:2624588字
文字の出現頻度
各文字の出現回数を観察
英語,日本語のデータで,各文字の出現割合(文字ユニグラム確率)を眺める.
割合なので,全ての文字の出現割合p(x)を全部足すと1になる.
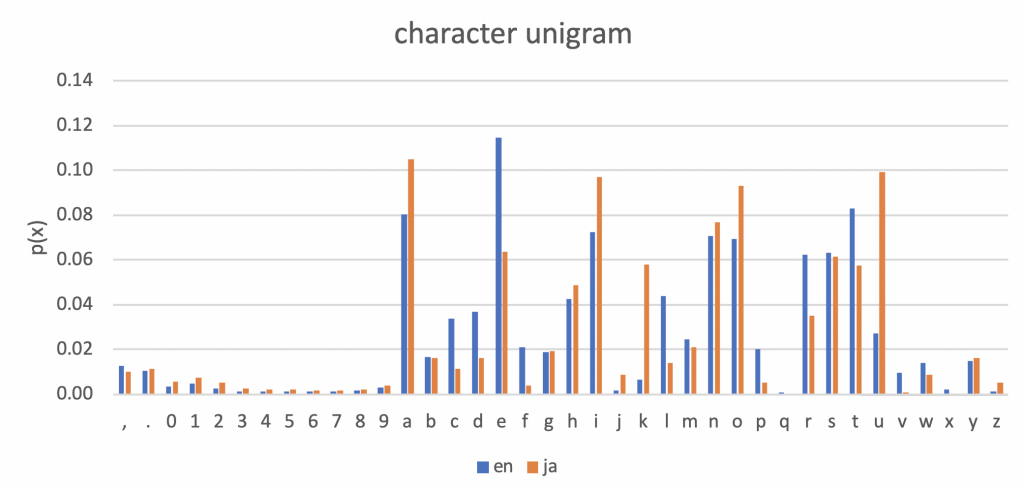
全体的には,まあ,そんなもんか,という感じ.
どちらの言語でも母音の使用頻度は高いが,英語でeが突出してるのはちょっと面白い.
もっと面白いのは日本語で子音kが多く使われていること.
これは星野ルネさんが以下の漫画で紹介していた,日本語は「カ行の存在感が強い」というイメージとも合致する.
聞きなれないジャンルの音楽って、どの曲も同じように感じる。でも聞きなれると1つ1つ全く違う曲だと感じられる。フォローで応援、ジョギング頑張ります。リツイートで絶対音感のカナリアが生まれます。いいねでサ行がはかどります。#漫画 #フランス語 #音感 pic.twitter.com/q8GvEsWilk
— 星野ルネ (@RENEhosino) May 7, 2019
二文字の繋がりを観察
次に,ある文字の次にどの文字が出やすいか(文字バイグラム確率)を観察する.
以下は遷移行列で,各行はある文字が次の文字にどれだけの割合で遷移するかを示す.
数字キーや記号の遷移を見る意味はあまりないので,a~zのアルファベットだけを載せた.
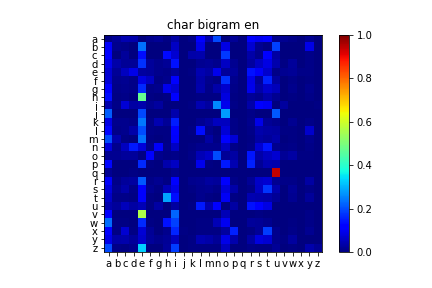
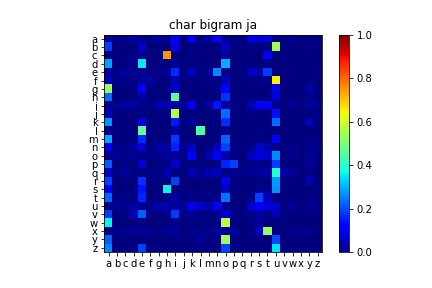
英語(上)と日本語(下)に共通する特徴として,子音からは比較的高い確率でaeiouの母音に遷移することがわかる.
(まあ,そもそも母音の出現回数が多いので母音の列が強く光ることは当たり前.)
英日を比較すると,日本語の方が母音の列が全体的に強く光っていることがわかる.
これは日本語が子音と母音を交互に発音するモーラ言語であることに起因する.
HMMによるキー入力指の推定
ここからが本題.
テキストを効率的に入力できるキー配列が理想と考えるのであれば,既に存在するテキストを入力しやすいように文字を各指に割り当ててやれば良い.
たとえば「テキストに含まれる各文字が,どの指で入力されるべきか」を推定できれば,ある程度この割り当ては作成できる.
文字列は系列データだから,系列に対してその出どころを推定するアルゴリズムがあると良い.
今回はテキストに対して隠れマルコフモデル(Hidden Markov Model; HMM)を学習し,各文字がどの指から生成されたかを推論する.
HMMだと思って今回の問題を考えると,テキストに含まれる各文字はそれぞれいずれかの指から入力される.
もちろん指の数に対して文字の種類の方が多いから,一つの指がいくつかの文字を担当することになる.
それだけではなく,ある指を使った後にどの指を使いやすいか,という点も考慮に入れる.
例えば同じ指を連続して使うよりも,異なる指,できれば反対の手のいずれかの指を使って交互に入力した方が負担は少ない.
テキストにはどの指で入力されたかという情報はないが,テキストに対してHMMを学習することで,各文字がどの指に割り当てられるべきかを知ることができる.と仮定する.
学習する際に、使う指の遷移について確率をあらかじめ与えてやることで、理想的な運指を学習することができそう。
面倒なので用語で説明してしまうと,運指を離散的な潜在変数の系列とし、そこから観測系列である各文字が生成されると考えてHMMを学習する.
後述する通り,潜在変数の遷移確率を固定してやることである程度面白い結果が得られる.
学習にはpythonのパッケージであるhmmlearnを使った.
右左の打ち分けを考慮
単純な分析として,各文字がどちらの手に割り当てられるべきかを考える.
ここでは各指に関しては考えず,ざっくりと左右どちらの手で入力すると効率が良いかを調べる.
Dvorak配列の設計理念を参考にすると,タイピングは左右の手で交互に行うことで効率的な入力ができるらしい.
そこで,左右の手を80%の確率で交代して入力するという制約の元でHMMを学習する.
つまり,ある文字を右手で入力したら,80%の確率で次の文字を左手で入力する.もちろん,20%の確率で同じ右手で入力する.
この制約のもとでHMMを学習し,各文字がどちらの手に割り当てると良いかを見る.
以下は学習されたHMMによる,各手ごとの文字出現確率.
学習時に右手とか左手とかといった指定をする意味はないので,単純にhand1,hand2とした.
各文字ごとに,hand1とhand2での出現確率の差でソートをすると,グラフのようにだいたいどの文字がどちらの手で入力されるべきかが見えてくる.
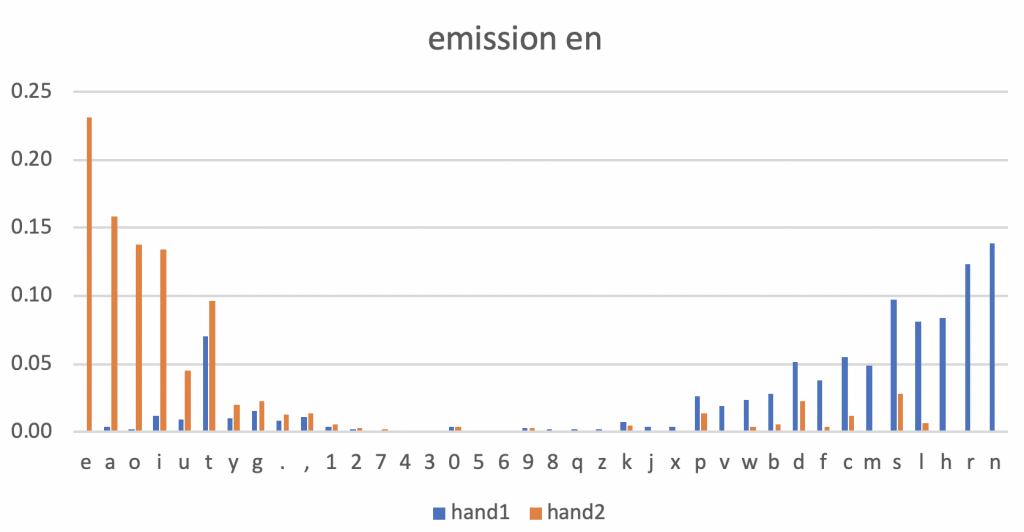
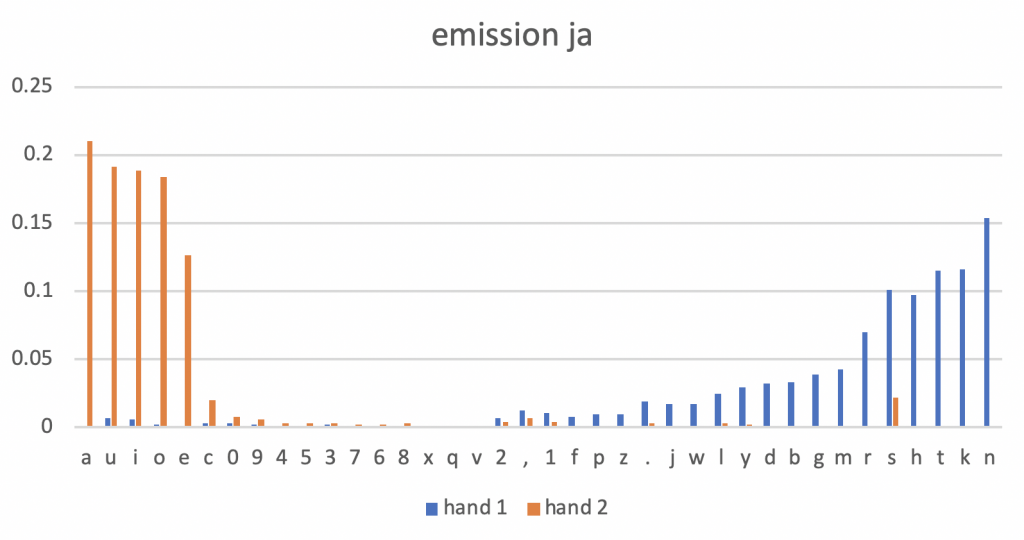
例えばhand1を右手,hand2を左手と考えると,英日どちらの言語も左手で母音を担当し,右手で子音を担当すると入力の効率が良さそうである.
これを見ると,Dvorak配列はなるほど考えられているなという気持ちになる.
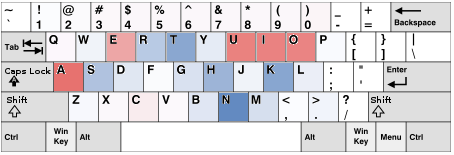
試みに,QWERTY配列とDvorak配列のキーを,それぞれ上で学習された確率で色付けしてみる.
色は各手から出力される各文字の確率の差を表す.
すなわち,赤に近いほどhand1(左手),青に近いほどhand2(右手)にその文字が割り当てられるべきである,とみる.
QWERTY配列(日本語)
Dvorak配列(日本語)
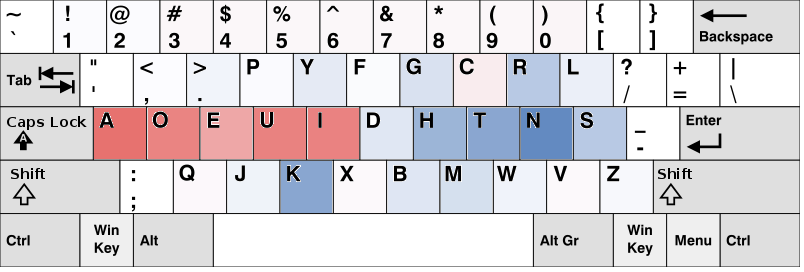
それぞれ、日本語のデータで学習した確率で色付けした。
Dvorak配列がいかに考えられてるかがよくわかる。
右左各指を考慮
最後に,各指を考慮してHMMを学習してみる.
親指以外の8本を使えるとし,同じ指を連続して使う確率は0.2*0.1,同じ手の異なる指を使う確率は0.2*0.3,異なる手の指を使う確率は0.8*0.25とした.
要は,「同じ指を使う<同じ手の異なる指を使う<異なる手の指を使う」という順に遷移しやすくなっている.
もちろん確率は8本分足すと1になる.
結果のいい見せ方が思いつかなかったので,学習された行列をそのまま載せる.
hand1,hand2はそれぞれ指としてfig1~fig4を持つ.
色が濃いほど,ある文字がその指に割り当てられる確率が高い.
図として見やすいように各文字ごとに最も確率が高い数値が1になるように数値を調整しているので,純粋に確率ではない.


例えばhand1を右手,hand2を左手と考えると,左手で全ての母音を担当し,右手でほとんどの子音を担当することになる.
さらに指ごとに担当が分かれていて,日本語ならaとuを担当する指が同じだと良さそうかもしれない,ということがわかる.
ここまでくるとごちゃごちゃしてきて,もっと真面目に考えないといけなくなるのでこの辺で打ち切ろう。
きもち
思いつきだったけど,いろんな言語についてもっと大きいコーパスを使えば,卒論くらいにはなりそうな内容だなと思った.
多分,もうどこかの誰かがやってることだと思うので,もしこういう内容の論文かなにかを知ってる方がいたら教えてください.
今回の結果だけをみると,Dvorak配列はよく考えられてるなという結論になる.
自分はQWERTY配列に慣れてしまってるので乗り換えるつもりはないけど,Dvorak配列が使いやすいという気持ちもよくわかる.
理想的なキー配列は言語ごとに変わると思うので,どの言語にとっても比較的辛いQWERTY配列を使っておけばいいんじゃないだろうか.
だいぶ雑に様々なものを説明してしまったので,間違ってることとか,わかりにくいところがあればコメントか何かでご連絡ください.
おしまい.
「少しだけ真面目に英日のキー配列を分析する」への1件のフィードバック